rpact: An R Package For Adaptive Clinical Trials
ROeS 2025, Graz
September 16, 2025
Overview 📦
- Comprehensive validated R package implementing methodology described in Wassmer and Brannath (2016)
- Enables the design of traditional and confirmatory adaptive group sequential designs
- Provides interim data analysis and simulation including early efficacy stopping and futility analyses
- Enables sample-size reassessment with different strategies
- Enables treatment arm selection in multi-stage multi-arm (MAMS) designs
- Enables subset selection in population enrichment designs
- Provides a comprehensive and reliable sample size calculator

Developed by RPACT 🏢
- RPACT company founded in 2017 by Gernot Wassmer and Friedrich Pahlke
- Idea: open source development with help of “crowd funding”
- Currently supported by 21 companies
- \(>\) 80 presentations and training courses since 2018, e.g., FDA in March 2022
- 29 vignettes based on Quarto and published on rpact.org/vignettes
- 28 releases on CRAN since 2018


![]()
RCONIS 🚀
- Grow RPACT company to offer a wider range of services
- Statistical consulting and engineering services: Research Consulting and Innovative Solutions
- Joint venture between RPACT GbR (rpact.com) and inferential.biostatistics GmbH (inferential.bio) founded by Daniel Sabanés Bové and Carrie Li
- Website: rconis.com

The R Package rpact – Functional Range

Recent Updates

Methodology of Delayed Response Designs
Given boundary sets \(\{u^0_1,\dots,u^0_{K-1}\}\), \(\{u_1,\dots,u_K\}\) and \(\{c_1,\dots,c_K\}\), a \(K\)-stage delayed response group sequential design has the following structure:


According to Hampson and Jennison (2013), the boundaries \(\{c_1, \dots, c_K\}\) with \(c_K = u_K\) are chosen such that “reversal probabilities” are balanced, to ensure type I error control.
More precisely, \(c_1,\ldots,c_{K - 1}\) are chosen as the (unique) solution of: \[\begin{align*} \begin{split} &P_{H_0}(Z_1 \in (u^0_1, u_1), \dots, Z_{k-1} \in (u^0_{k-1}, u_{k-1}), Z_k \geq u_k, \tilde{Z}_k \leq c_k) \\ &= P_{H_0}(Z_1 \in (u^0_1, u_1), \dots, Z_{k-1} \in (u^0_{k-1}, u_{k-1}), Z_k \leq u^0_k, \tilde{Z}_k \geq c_k). \end{split} \end{align*}\]
Delayed Response: Plot
gsdWithDelay |> plot()
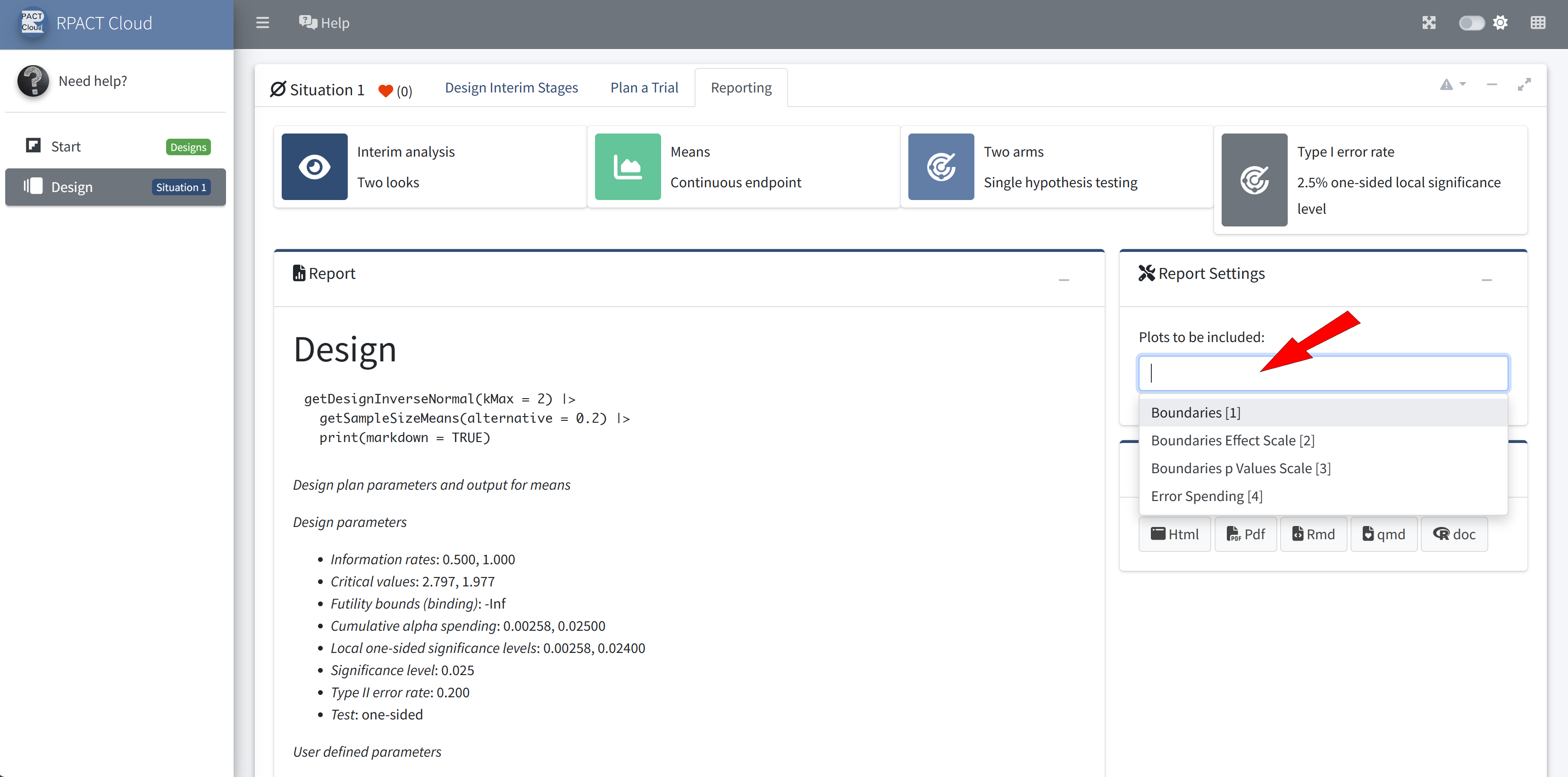
Start Page

Design

Reporting
What’s Next?

Second Edition of the Book

- Provides up-to-date overview of group sequential and confirmatory adaptive designs in clinical trials
- Describes available software including R packages and has
rpactcode examples - Supplemented with a discussion of practical applications
RPACT Connect